会議、打ち合わせ、研修音声などをAIで文字起こししたい。
しかし、NottaやPLAUD Noteのようなクラウド型サービスは便利な一方で、長時間利用すると月額費用や文字起こし時間数の制限が気になります。
そこで今回は、Windows PCで無料のローカルAI文字起こし環境を作れるWhisper Desktopの導入方法を、GitHubからの入手方法、モデルファイルの選び方、初期設定、実際の操作方法まで詳しく解説します。
この記事でわかること
- Whisper Desktopとは何か
- OpenAI版WhisperとConst-me版Whisper Desktopの違い
- GitHubからWhisper Desktopをダウンロードする方法
- モデルファイルの選び方
- small・medium・largeなどの違い
- 日本語文字起こし向けの初期設定
- 実際に音声ファイルを文字起こしする手順
- 実際に使い物になるのか
Whisper Desktopとは?
Whisper Desktopは、OpenAIが公開している音声認識AI「Whisper」を、Windows上で使いやすくしたアプリです。
OpenAIのWhisper本体は高性能ですが、基本的にはPythonやコマンド操作が必要です。
一方、Const-me版のWhisper Desktopは、Windowsアプリとして起動し、画面上で音声ファイルを選択して文字起こしできます。
つまり、プログラミングに詳しくなくても、比較的簡単にWhisperを使えるのが特徴です。
OpenAI版WhisperとConst-me版Whisper Desktopの違い
Whisperを調べると、まずOpenAI公式のGitHubページが出てきます。
OpenAI公式Whisperはこちらです。
https://github.com/openai/whisper
ただし、これは開発者向けです。
Windowsで簡単に使いたい場合は、Const-me版のWhisper Desktopを使う方が導入しやすいです。
Const-me版Whisperはこちらです。
https://github.com/Const-me/Whisper
| 項目 | OpenAI版 Whisper | Const-me版 Whisper Desktop |
|---|---|---|
| 配布元 | OpenAI | Const-me |
| URL | https://github.com/openai/whisper | https://github.com/Const-me/Whisper |
| 対象者 | 開発者・CLIに慣れた人 | Windowsで手軽に使いたい人 |
| 操作方法 | コマンド操作 | GUI操作 |
| Python | 必要 | 不要 |
| ffmpeg | 必要 | 通常は意識しなくてよい |
| 導入難易度 | やや高い | 比較的簡単 |
| おすすめ用途 | 自動化・開発・スクリプト処理 | 手動で音声ファイルを文字起こし |
| 初心者向け | △ | ◎ |
この記事では、Windowsで簡単に使えるConst-me版 Whisper Desktopを前提に解説します。
Whisper Desktopの入手先
Whisper Desktopは、GitHubのConst-me版Whisperページから入手します。
公式ページはこちらです。
https://github.com/Const-me/Whisper
GitHubのReleasesページはこちらです。
https://github.com/Const-me/Whisper/releases
Releasesページには複数のZIPファイルがあります。
通常利用するのは、次のファイルです。
WhisperDesktop.zipGitHubのReleasesには、WhisperDesktop.zipのほかに、cli.zip、Library.zip、WhisperPS.zipなどもありますが、通常のWindowsアプリとして使う場合はWhisperDesktop.zipを選びます。
Whisper Desktopのダウンロード手順
- ブラウザでConst-me版Whisperのページを開く
- 右側または上部付近の「Releases」をクリック
- 最新リリースを開く
- Assetsの中からWhisperDesktop.zipを探す
- WhisperDesktop.zipをクリックしてダウンロード
ダウンロード先は、通常はWindowsの「ダウンロード」フォルダになります。
Whisper Desktopのインストール手順
Whisper Desktopは、一般的なインストーラー形式ではありません。
ZIPファイルを展開して、実行ファイルを起動するタイプです。
1. ZIPファイルを展開する
ダウンロードしたファイルを右クリックします。
WhisperDesktop.zip右クリックメニューから、次を選びます。
すべて展開展開先は、ご自身の分かりやすい場所がおすすめです。
2. WhisperDesktop.exeを起動する
展開したフォルダの中に、次の実行ファイルがあります。
WhisperDesktop.exeこれをダブルクリックして起動します。
WindowsのSmartScreen警告が表示される場合があります。
その場合は、内容を確認したうえで、問題なければ「詳細情報」から「実行」を選びます。
モデルファイルとは?
Whisper Desktop本体を起動しただけでは、まだ文字起こしはできません。
Whisperでは、音声認識に使うAIモデルファイルが必要です。
モデルファイルは、Hugging Faceからダウンロードします。
モデルファイルの入手先はこちらです。
https://huggingface.co/ggerganov/whisper.cpp/tree/main
このページには、多数のモデルファイルがあります。
Whisper Desktopで使う場合は、基本的にggml-〇〇.binという名前のファイルを選びます。
Hugging Face(ハギングフェイス)は、世界中のAI開発者や企業が、AIモデルを公開・共有している巨大プラットフォームです。
簡単に言うと、「AI版GitHub」のようなサイトです。
現在では、AI業界では非常に有名なサービスで、OpenAI、Meta、Google系研究者なども利用しています。
【GitHubとの違い】
GitHubは、主にプログラムコードを共有するサイトです。
一方、Hugging Faceは、AIモデルや機械学習用データを配布することに特化しています。
日本語文字起こしで選ぶべきモデル
日本語音声を文字起こしする場合は、以下のようなファイルを選びます。
| モデル | ファイル名 | サイズ目安 | 特徴 | おすすめ度 |
|---|---|---|---|---|
| tiny | ggml-tiny.bin | 約78MB | 非常に軽いが精度は低め | △ |
| base | ggml-base.bin | 約148MB | 軽くて速いが、会議用途では精度不足の場合あり | △〜○ |
| small | ggml-small.bin | 約488MB | 速度と精度のバランスが良い | ◎ |
| medium | ggml-medium.bin | 約1.53GB | 日本語精度が高く、実用性が高い | ◎ |
| large-v3 | ggml-large-v3.bin | 約3.1GB | 高精度だが非常に重い | ○ |
| large-v3-turbo | ggml-large-v3-turbo.bin | 約1.62GB | large系の軽量高速版 | ○ |
最初におすすめのモデル
最初に試すなら、次のどちらかがおすすめです。
| 目的 | おすすめモデル |
|---|---|
| まず軽く試したい | ggml-small.bin |
| 日本語精度を重視したい | ggml-medium.bin |
私のおすすめは、最初はggml-small.binで動作確認し、問題なければggml-medium.binを使う方法です。
注意:.en付きモデルは日本語向けではない
モデル一覧には、以下のようなファイルもあります。
ggml-medium.en.bin
ggml-small.en.bin
ggml-base.en.binこれらは英語向けモデルです。
日本語を文字起こししたい場合は、.enが付いていないモデルを選びます。
| ファイル名 | 日本語用途 |
|---|---|
| ggml-medium.bin | 使える |
| ggml-medium.en.bin | 日本語用途には不向き |
量子化モデルとは?q5_0・q8_0の意味
モデル一覧には、以下のようなファイルもあります。
ggml-medium-q5_0.bin
ggml-medium-q8_0.binこれは量子化モデルと呼ばれる軽量版です。
簡単に言うと、モデルサイズを小さくして、メモリ使用量を減らしたものです。
| 種類 | 特徴 |
|---|---|
| 通常版 | 精度重視。まずはこちらがおすすめ |
| q5_0 | かなり軽量。精度は少し落ちる可能性あり |
| q8_0 | 通常版より軽め。q5_0より精度を保ちやすい |
初めて試される方は、最初は量子化版ではなく、以下のような通常版を選ぶのが無難です。
ggml-small.bin
ggml-medium.binモデルファイルの保存場所
ダウンロードしたモデルファイルは、わかりやすい場所に保存します。
おすすめは以下です。
C:\WhisperModels\例えば、mediumモデルを保存した場合は、次のようになります。
C:\WhisperModels\ggml-medium.bin後でWhisper Desktopからこのファイルを指定します。
Whisper Desktopの初回設定
WhisperDesktop.exeを起動すると、最初にモデルファイルの指定画面が表示されます。
ここで、先ほどダウンロードしたモデルファイルを選択します。
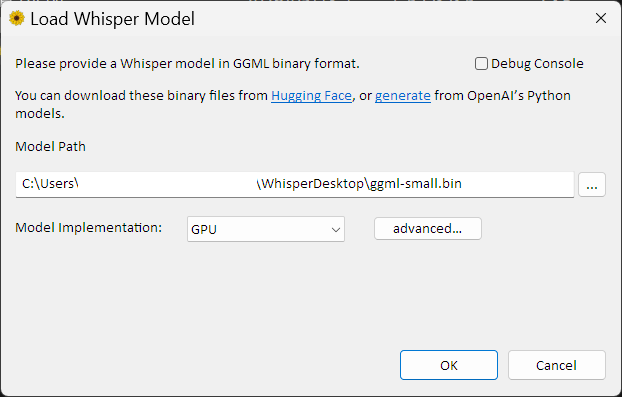
Model Path
「…」ボタンを押して、モデルファイルを選びます。
C:\WhisperModels\ggml-medium.binまたは、smallモデルを使う場合は以下です。
C:\WhisperModels\ggml-small.binModel Implementation
Model Implementationでは、GPUを選択します。
| 設定 | 特徴 | おすすめ |
|---|---|---|
| CPU(Reference) | 安定しやすいが処理は遅め | 最初の動作確認向け |
| GPU | NVIDIA GPUが使えると高速 | GPU搭載PC向け |
Model Implementationには、GPU、Hybrid、Referenceが表示される場合があります。
GPUは高速、HybridはGPUとCPUの併用、ReferenceはCPU実行用です。
ただし、配布されているDLLの種類によってはReferenceが使えない場合があります。
その場合はGPUまたはHybridを選びます。
文字起こし画面の基本設定
モデルを読み込むと、音声ファイルを文字起こしする画面が表示されます。
日本語音声の場合、重要なのは以下の設定です。
| 項目 | 設定 | 理由 |
|---|---|---|
| Language | Japanese | 日本語音声として認識させるため |
| Translate | OFF | ONにすると英訳される可能性があるため |
| Output Format | TXT | 議事録に使いやすいため |
LanguageはJapanese固定がおすすめ
Autoでも認識できますが、日本語音声の場合はJapanese固定がおすすめです。
特に会議や診察のように、音声が小さい、雑音がある、無音区間がある場合は、AutoよりJapanese固定の方が安定することがあります。
Language: JapaneseTranslateはOFFにする
TranslateをONにすると、文字起こしではなく翻訳モードになる場合があります。
日本語を日本語のまま文字起こししたい場合は、TranslateをOFFにします。
Translate: OFF実際の操作方法
Whisper Desktopで音声ファイルを文字起こしする基本操作は以下の通りです。
- WhisperDesktop.exeを起動
- モデルファイルを読み込む
- LanguageをJapaneseに設定
- TranslateをOFFにする
- Output FormatをTXTにする
- 「Transcribe File」の「…」をクリック
- 音声ファイルを選択
- 文字起こし開始
- 完了後、テキストファイルを確認
対応しやすい音声ファイル形式
Whisper Desktopでは、一般的な音声ファイルを扱えます。
- mp3
- m4a
- mp4
wavは対応していませんでした。
おすすめの録音ファイル管理方法
長時間録音を扱う場合は、ファイル名と保存場所を決めておくと便利です。
例えば、以下のようなフォルダ構成にします。
C:\Transcription\
├── audio\
│ ├── 2026-05-13_会議_01.mp3
│ └── 2026-05-13_会議_02.mp3
├── text\
│ ├── 2026-05-13_会議_01.txt
│ └── 2026-05-13_会議_02.txt
└── models\
└── ggml-medium.binファイル名には日付と内容を入れると、後から探しやすくなります。
2026-05-13_理事会_01.mp3
2026-05-13_理事会_01.txtWhisper Desktop導入時によくある疑問
無料で使えますか?
はい。Whisper Desktop自体は無料で利用できます。
また、ローカルPCで処理するため、NottaやPLAUDのような分数課金は基本的にありません。
インターネット接続は必要ですか?
最初にWhisper Desktop本体とモデルファイルをダウンロードする時は必要です。
その後、ローカル処理で使うだけなら、基本的にはオフラインでも利用できます。
音声データはクラウドへ送信されますか?
Const-me版Whisper Desktopでローカル処理する場合、音声データは基本的にPC内で処理されます。
そのため、クラウド型文字起こしサービスと比べて、機密情報を扱う場合の安心感があります。
日本語ならどのモデルを選べばよいですか?
日本語の場合は、.enが付いていないモデルを選びます。
例えば、以下です。
ggml-small.bin
ggml-medium.bin以下のような.en付きモデルは英語向けです。
ggml-small.en.bin
ggml-medium.en.bin導入後のおすすめ初期設定まとめ
| 項目 | おすすめ設定 |
|---|---|
| モデル | ggml-small.bin または ggml-medium.bin |
| Language | Japanese |
| Translate | OFF |
| Output Format | TXT |
| Model Implementation | GPU |
実際にWhisper Desktopを使ってみた結果
実際にWhisper Desktopを使って、複数パターンの音声を文字起こししてみました。
結論としては、
- 録音条件が良いとiPhoneの文字起こしよりは優秀
- 録音条件が悪いと急激に精度が落ちる
という印象でした。
特に、
- 音量が小さい
- 雑音が多い
- マイクから遠い
- 無音部分が長い
といった条件では、かなり崩れる場合がありました。
① 家族4人の会話をポケット内のスマホで録音した場合
まず試したのが、家族4人で会話している音声です。
あえてスマホをポケットに入れた状態で録音しました。
実際の会話は以下のような内容でした。
<実際の会話(抜粋)>
おばあちゃんにお菓子持って行ってくれてありがとう。
喜んでた?
美味しいと言ってたよ。
ところが、Whisper Desktopの文字起こし結果は次のようになりました。
<Whisperの文字起こし結果>
おばあちゃん
おばあちゃん
おばあちゃん

なぜか「おばあちゃん」だけが大量に繰り返される状態になってしまいました。
恐らく、
- ポケット内録音
- 音声がこもる
- 家族全員の声が遠い
- 雑音や衣擦れ音が入る
などが原因と思われます。
Whisper系では、条件が悪いと、このような「同じ単語を繰り返す」現象が発生することがあるようです。
② 会議中に机の上へスマホを置いて録音した場合
次に、会議中にスマホを机の上へ置いて録音した音声を試しました。
こちらはかなり精度が高く、驚きました。
内容は掲載できませんが、少なくともiPhone標準の文字起こしよりは正確で、金額などもかなり正しく認識していました。
一方で、気になる点もありました。
特に違和感があったのが「話者区別」です。
なぜか、私自身や会議メンバーが以下のように認識されていました。
<Whisperの話者区別例>
(記者)
(徳島新聞社)
(市長)
実際には新聞社や市長とは全く関係ありません。
恐らく、Whisperが文脈や話し方から、ニュースやインタビュー風の会話だと誤推定したものと思われます。
また、無音部分や小声部分では、存在しない単語が勝手に文字起こしされることもありました。
このことから、Whisper Desktopは、
- はっきり録音された会議音声
- 机上録音
- 比較的静かな環境
ではかなり優秀ですが、
- 遠距離録音
- ポケット録音
- 小声
- 無音が多い音声
では、精度が急激に落ちる場合があると感じました。
特に、録音品質の影響はかなり大きい印象です。
GPUをフルに使って文字起こししてくれます
Dell XPS9560でWhisper Desktopを動作させてみました。
今回使用した主な構成は以下です。
| 項目 | 内容 |
|---|---|
| PC | Dell XPS 9560 |
| CPU | Intel Core i7-7700HQ |
| メモリ | 8GB |
| GPU | NVIDIA GeForce GTX 1050 (メモリ4 GB GDDR5) |
| Whisperモデル | ggml-medium.bin |
実際に文字起こしを実行している際のタスクマネージャー画面がこちらです。
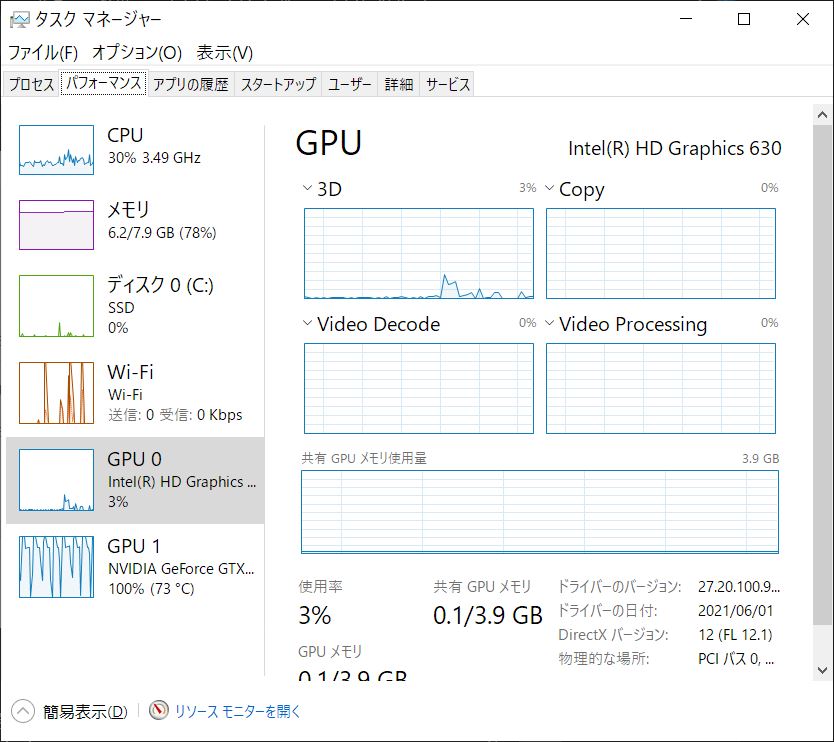
GPUをしっかり使用していた
タスクマネージャーを確認すると、Whisper Desktop実行中はNVIDIA GPU側の使用率が大きく上昇していました。
つまり、Whisper DesktopはCPUだけではなく、GPUを活用してAI推論を行っていることが分かります。
今回の環境では、Intel内蔵GPUではなく、GeForce GTX側へ処理がオフロードされていました。
ローカルAIを個人PCで動かしている感覚が面白い
個人的に驚いたのは、数年前ならクラウドサービスや高価なサーバが必要だったようなAI音声認識処理が、一般的なノートPCでも動いてしまう点です。
しかも、今回は完全ローカル処理です。
つまり、
- 音声をクラウドへ送信しない
- PC内だけで文字起こし
- 月額課金なし
という環境を、自宅PCだけで構築できています。
ただしlarge系モデルはかなり重い
一方で、large-v3系モデルはかなり負荷が高く、XPS9560では処理に非常に時間がかかりました。
場合によっては、一晩経っても半分程度しか進まないこともありました。
そのため、実用性を考えると、XPS9560クラスでは以下の使い分けが現実的だと感じました。
| 用途 | おすすめモデル |
|---|---|
| 普段使い | ggml-small.bin |
| 精度重視 | ggml-medium.bin |
| large-v3系 | 短時間音声向け |
GPU搭載PCなら試す価値はある
今回の検証では、GTX1050搭載の比較的古いノートPCでも、Whisper DesktopがしっかりGPU動作していました。
そのため、
- NVIDIA GPU搭載PC
- ゲーミングノート
- クリエイター向けPC
を持っている人なら、一度Whisper Desktopを試してみる価値は十分あると思います。
まとめ:Whisper Desktopは無料としては使えるが専用ツールには及ばない
Whisper Desktopを実際に試してみた結果、無料でここまでできるのかと驚かされました。
特に、
- ローカルPCだけで動作する
- クラウドへ音声を送信しない
- 月額課金なしで使える
- GPUを活用した高速処理が可能
という点は非常に魅力的です。
一方で、実際に会議をスマホで録音した音声を試したところ、音声品質や録音環境の影響を大きく受ける印象でした。
また、モデル選択やGPU設定など、初心者には少し難しい部分もあります。
そのため、
- 簡単に高精度な文字起こしをしたい
- 設定で悩みたくない
- スマホだけで完結したい
という場合は、NottaやPLAUD Noteのような専用サービスの方が完成度は高いと感じました。
ただし、
- 無料で試したい
- ローカルAIを触ってみたい
- クラウドへ音声を送りたくない
- 長時間利用時のコストを抑えたい
という用途では、Whisper Desktopはかなり使えます。
今後もローカルAI関連は急速に進化していくと思われるため、引き続き検証していきたいと思います。